Causality in Explainable AI
With the use of predictive AI gaining attention in clinical settings, questions around trust are starting to proliferate. This is particularly acute as medical practitioners might be asked to base a decision, at least in part, on the output of an AI model, but will retain the legal consequences for any wrong decisions. Within this context, it is perfectly understandable that healthcare practitioners ask for some level of transparency regarding any particular AI output. This could help them calibrate their trust. But what role, if any, does causal thinking play in this process?
Explainable AI (XAI) methods are one tool designed to show the workings, in some sense, of an AI model. XAI methods are often applied after a model has been trained (as opposed to, for instance, interpretable AI models which in some way intrinsically make sense). These are post-hoc XAI tools. They can either explain the overall behaviour of the AI model (called global explanations), or why one particular input has a given output (called a local explanation), or sometimes both.
However, there is some debate as to whether XAI is really needed in healthcare AI or indeed whether it may even be harmful. These have been discussed elsewhere and are listed below, but this blog discusses one in particular (in bold):
Evidence Based Medicine is empirical and does not necessarily need to understand mechanisms;
Explainability comes at the cost of predictive power;
Current XAI techniques are inconsistent and unreliable;
XAI techniques are difficult to rigorously assess;
Explanations can lead to incorrect causal inference.
To understand why this last point can be dangerous, we need to see things from the healthcare practitioner’s perspective. Imagine an AI system has identified a patient as being at risk of sepsis and that an XAI tool identifies low blood pressure as the leading contributing factor. The natural temptation is to weave that into a clinical narrative: sepsis has caused the patient’s blood pressure to drop. This is a perfectly plausible real-world claim, and one which should induce some degree of urgency in any treatment. However, there is an assumption here. It assumes that the AI model has learned clinically relevant features to predict sepsis and that the XAI faithfully reports this. The risk is that a clinician may treat the explanation as identifying the cause of some disease process, rather than merely being a feature used by the model.
We know that AI models do not generally learn features that humans would use. Instead, they are prone to short-cut learning, where they exploit any correlations in the training data, including spurious correlations. This can lead to models which are right for the wrong reasons.
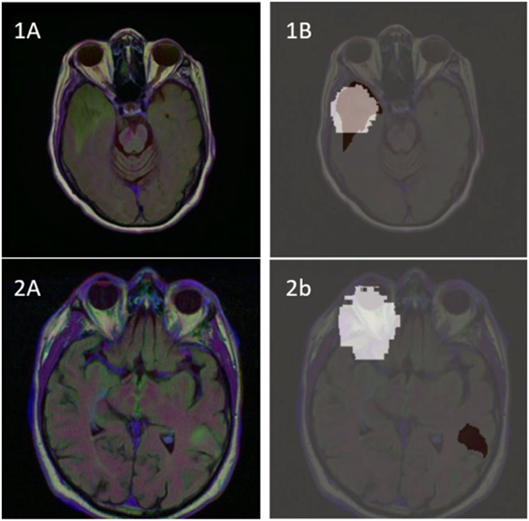
This can be illustrated by considering an AI model which has been trained to identify a type of brain cancer, with an XAI tool called ReX (figure 1). In the top row we can see the feature highlighted by ReX (light grey) coincides pretty well with the tumour (dark red) . In the bottom row though the model again gets the classification right, but ReX shows that the model is using the eyeball, rather than the actual tumour. It is definitely not the case that the eyeball is causing the tumour in the real world, but rather that the eyeball is causing the model to think that the image is cancerous. This is actually a common flaw in many AI models for brain imaging and led to ‘skull stripping’ – in which distinct features such as eyes and skulls are digitally removed before training.
Figure 1. From: MRxaI: Black-Box Explainability for Image Classifiers in a Medical Setting, N Blake, H Chockler, DA Kelly, SC Pena, A Chanchal, 2nd Workshop on Explainable Artificial Intelligence for the medical domain. 2026
Some researchers believe that the tendency for humans to think causally with regard to the real world will lead healthcare practitioners to make incorrect inferences about the causes of an AI prediction. That is they will mistake what causes a model to make a classification for causes in the real world. It is a subtle distinction but healthcare practitioners are no strangers to nuanced thinking. Once they understand the potential danger they can then decide on the usefulness of explanations for themselves.
What is being explained?
The first thing to distinguish is what is being explained. In the current typical medical AI framework, XAI explains the model, not the world. It is only applicable to the world to the extent that the AI model itself has learned something about the world which aligns with our understanding (which it may or may not have). This surprisingly doesn’t have to be much to get a very accurate model; the world (and hence the training data) is full of correlations.
Is the explanation causal?
So XAI explains the model. There is a further subtlety we can consider: some XAI methods are causal, while some are not. For instance, ReX is causal – it will highlight those features which are sufficient to cause the model to make a given classification. Other common XAI tools, such as SHAP or LIME, do not have this property but provide feature attributions or local approximations that should not be interpreted causally.
By having a precise definition of an explanation, it is possible to examine causal claims. This uses the framework of Actual Causality, which differs from the more common Pearlian causal thinking some may be familiar with. But it must always be remembered that any causal claims are only in regard to what caused the model to make a classification.
With this caveat in mind, XAI may be useful to healthcare practitioners. It is to be expected that medical AI will have modes of failure – as do humans. No one expects perfect prediction, and modern healthcare systems have many layers of redundancy to make systems somewhat robust to mistakes, human or otherwise. But having tools which allows practitioners to examine why certain classifications are being made could help determine how much they are willing to trust it.